What is algorithmic bias?
Organisations are increasingly making use of algorithmic technologies, both in the form of generative AI and predictive analytics. As these tools become more embedded within our working practices and the platforms we use, awareness of ‘algorithmic bias’ has increased along with it.
What are some real-world examples of algorithmic bias?
The COMPAS system in the United States – which stands for Correctional Offender Management Profiling for Alternative Sanctions – is a risk assessment system used in the criminal justice system to aid judges in making decisions about bail and sentencing. An investigation by ProPublica found the system discriminated against Black defendants, finding them more likely to reoffend than white defendants with a similar criminal history (Angwin et al., 2016: Kirkpatrick, 2016). This has raised serious concerns about racial bias in the criminal justice system, and how algorithmic technologies can exacerbate and further entrench prejudice attitudes.
Due to the COVID-19 pandemic, UK A-Level students were unable to sit their final exams, and as such, their grades calculated algorithmically using a combination of data sources including teacher predicted grades, the school’s passed performance, and previous years subject data. However, this approach caused widespread controversy due to students from state schools receiving lower scores than their peers from private schools, who were often awarded their teacher assessed grade to small class sizes. After complaints from students, parents and teachers, all students were awarded their teacher predicted grades. In 2023, the Dutch authorities reformed the childcare benefit system to include algorithmic methods to predict fraud cases. This case is particularly notable considering the lengths the department went to to ensure the system was implemented in line with bias mitigation best practice, however this didn’t prevent the algorithm from discriminating against certain groups. Originally, the algorithm was more likely to disproportionately identify men and non-Dutch people as being likely to commit fraud. The algorithm was later re-weighted to correct for this, however it was then found to disproportionately identify Dutch people and women as being likely to have committed fraud. This case highlights some of the particularly challenging aspects of algorithmic bias, and how even with the best will and intention, algorithmic technologies pose often unpredictable difficulties. Find out more: Inside Amsterdam’s high-stakes experiment to create fair welfare AI, MIT.
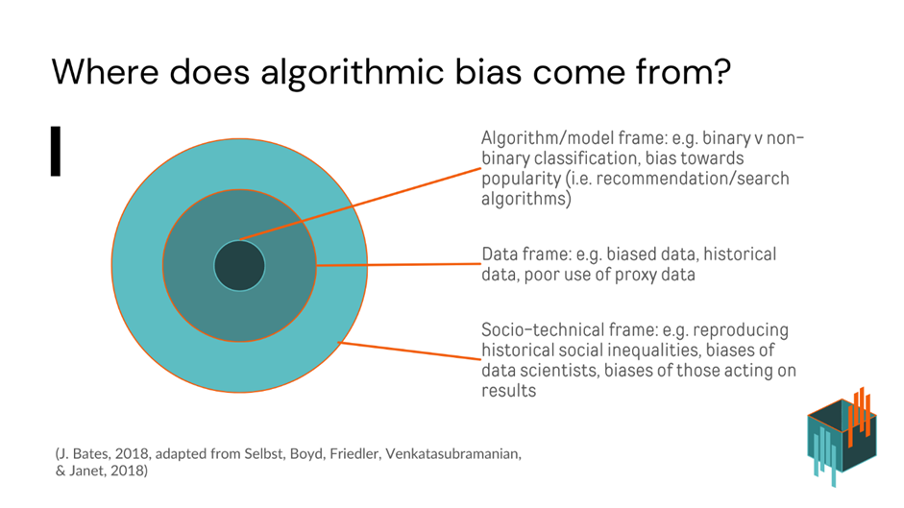
What causes Algorithmic Bias?
Algorithmic bias refers to unfair outcomes that result from automated decision-making processes. These outcomes may disadvantage certain groups based on race, gender, socioeconomic status, or other characteristics, even when these characteristics are not explicitly included in the model. Algorithmic bias emerges due to a complicated set of conditions, one way of understanding this problem is to consider it in terms of three possible framings – the data, the algorithm, and the socio-technical environment in which the algorithmic technology operates. These three framings aren’t clear cut, and there’s interplay between these framings.
The following is a visual representation of these framings:
Data
Causes of bias which emerge in the data-based framing of algorithmic might include:
- Non-representative datasets: Datasets which don’t include certain groups will preform badly on those groups, as the algorithm will have less ‘experience’ with those groups, and will be more prone to errors and biases. For example, Buolamwini (2017) found that facial recognition algorithms were more likely to mis-identify black women compared to all other gender and racial combinations, due to the lack of black women in the underlying datasets the algorithm was trained on.
- Historically biased datasets: All data is historic in nature (Oman, 20xx). As such, datasets contain the social biases of the time they were captured. This can be in what’s in the dataset, such as over-representation of Black men in arrest statistics due to over-policing of BAME communities and entrenched racism in the criminal justice system (Benjamin, 2021). Or, it can be due to the absence of data, such as under-representation of women in certain industries. If we go further back, we could also consider diagnostic categories such as ‘hysteria’, and while modern day data scientists are unlikely to come across a dataset with a patient diagnosed with hysteria, it’s worth reflecting on how categories change across time. Using data which contains the prejudices of the past makes it difficult for an algorithm to predict an equal future.
- Proxy variables: When datasets include variables such as postcode or educational attainment, algorithmic systems can often infer sensitive characteristics such as race, socioeconomic background, or other personal information which was not included in the original dataset. Even when protected characteristics are not explicitly included, proxy data can still influence model outputs in problematic ways (O’Neil, 2017)
The Algorithm
Causes of bias which emerge in the algorithmic-based framing of algorithmic might include:
- Model decisions: Decisions about what variables go into a model, and how these are handled, influences the types of outputs a model can produce. O’Neil examines this in her book Weapons of Math Destruction using the example of a algorithm which decides what to eat for breakfast – if pop tarts are excluded from the algorithm, that’s imposing the idea that pop tarts are not a suitable breakfast food. Similarly, when recommender systems are designed to promote videos, they’re prone to popularity biases.
- Model purpose: Some models are far harder to make ‘fair’ than others, and this can be down to what the model is designed to achieve to start with. Fraud detection algorithms have been seen as particularly contentious, in part due to their effects on often marginalised groups, who often have very little recourse if they’re flagged by these systems. This can lead to incredibly harmful consequences, such as families losing access to money which they need for food and shelter.
- Context: Some models are designed and trained for use in an environment which is quite different from some of the environments its later deployed in. This can lead to emergent biases, where the algorithm is not suitable for its new context – however this may not always be obvious at first, and emergent biases may also develop due to changing circumstances since the model was first developed (Friedman and Nissenbaum, 1996).
Socio-technical framing
Causes of bias which emerge in the soio-technical-based framing of algorithmic might include:
- Human decision-making: AAlgorithmically calculated outputs are often passed on to humans who act as final decision makers, which is often encouraged as a bias mitigation mechanism called having a ‘human in the loop’ to protect against purely algorithmic decisions discriminating against those impacted by them. However, the research on how humans react to machine generated decisions is unclear, and humans may be swayed by algorithmically calculated decisions, assuming there is something they ‘missed’ themselves (Eubanks, 20xx). It’s important to consider how rigorous a ‘human in the loop’ approach would be in your own organisation, not just more generally.
- Organisational and cultural factors: The social attitudes which will influence data scientists’ decisions about data and algorithms belong to the socio-technical frame. This may include assumptions, prejudices, or just lack of familiarity with the groups the algorithm is being designed for – particularly when the big tech industry is overwhelming white and male. A lack of diversity has been posited as part of the reason the development and continued sustainment of cultural biases in algorithmic technologies.
- Systemic inequality: Algorithms may re-enforce systemic inequality, particularly when these systems are used to detect benefit fraud, and decide who is allowed acs to limited resources. This is an issue which strongly influences both the da and algorithmic frames.
How can we address algorithmic bias?
A range of bias mitigation techniques have been developed and are in use today. Many of these have been technical de-biasing methods – focusing on issues such as data quality, comparative statistics, and fairness benchmarking. However, recent research has demonstrated that that these technical approaches by themselves do not substantially mitigate the risks of algorithmic bias, and ultimately, that of algorithmically caused harm upon those subject to the decisions made by algorithmic technologies. It’s important for organisations to adopt both technical and socio-technical bias mitigation strategies, informed by longstanding theories and methods used in the social sciences. In this toolkit, you can learn more about the types of social science approaches which can assist your organisation in bias mitigation.
Further Resources
Dolata, M., Feuerriegel, S., & Schwabe, G. (2021). A sociotechnical view of algorithmic fairness. Information Systems Journal. Manuscript accepted for publication. arXiv. https://arxiv.org/abs/2110.09253
O’Neil, C. (2016). Weapons of math destruction: How big data increases inequality and threatens democracy. New York, NY: Crown Publishing Group. ISBN: 978-0553418811.